Google search algorithm leak – SEO secrets revealed


The internet is abuzz with news about a major data leak at Google, shedding light on how their ranking algorithms work. Many myths and facts about SEO can now be verified by looking directly at the leaked information.
Google data leak – what happened?
Accidentally, Google bots published internal reference documentation for the Google Search’s Content Warehouse API on GitHub. This has provided more clarity on the features that determine page visibility in search results.
Although over 14,000 ranking factors were revealed (!), we don’t know to what extent they influence positioning due to the lack of scoring.
It’s worth noting that the API documentation was leaked, not source code, so many of these functions might be outdated. The data was published on March 27, 2024, and removed only on May 7, 2024.
We don’t know how the individual modules work or their associations. However, we do have a list of names for ranking factors along with brief descriptions, such as:

Key insights from the Google Data Leak
Below are the most important SEO lessons from the Google data leak.
Domain authority matters
In the “Compressed Quality Signals” section, there’s a function called “siteAuthority” that is responsible for better ranking of trusted sites.
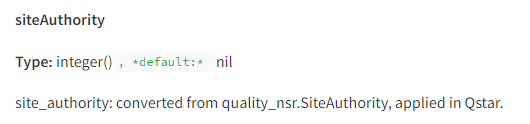
Again, we don’t know how this function is measured and used in the overall SEO scoring, but we do know for sure that such a parameter exists and is used as a ranking factor. Similar reservations apply to the following parameters.
Clicks influence positions
We know that Google uses machine learning algorithms. It has long been suspected that clicks are an important attribute for automated ranking – after all, engaging content is visited more often and thus should rank higher. Indeed, Google uses clicks as a strong signal in its ranking systems.
In the function below, we have various click signals that influence SEO:
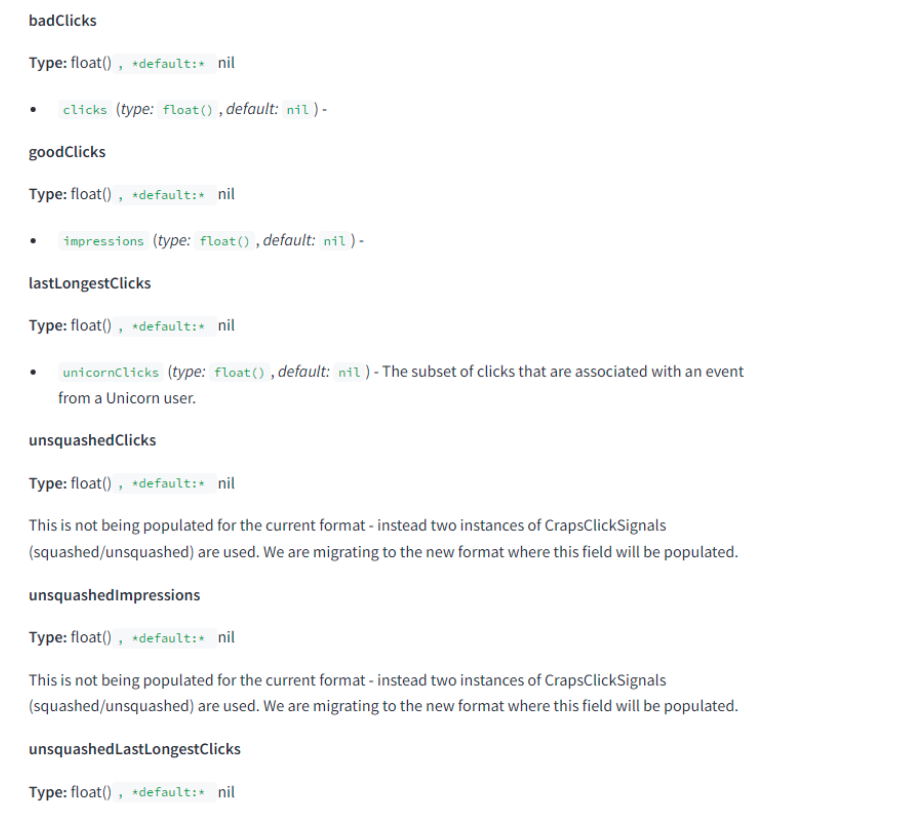
While the initial signals are understandable, it’s worth explaining the rest. According to Google’s definition, squashing is a function that prevents one large signal from dominating others. In other words, the algorithms normalize click data to prevent rank manipulation through artificial, excessive clicks.
We can thus assume that the system is reasonably balanced and reflects natural interest in content by users, and extra clicking on one’s own content won’t help achieve higher positions.
Articles from certain authors position better
This is a significant surprise for the SEO industry. Much has been said about factors like E-A-T or topical authority, which relate to the site’s reputation, affecting its expertise and trust. Now we know that the same applies to individual authors!
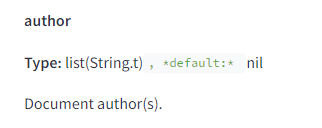
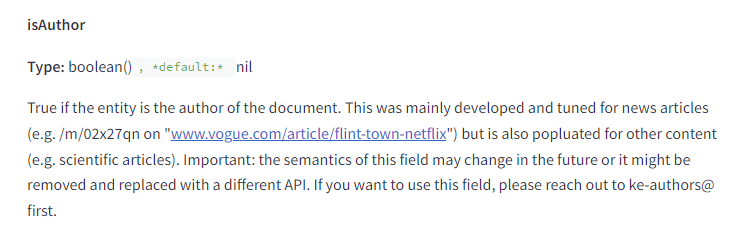
Author evaluation appears to be comprehensive – for example, one function checks if the author of the page is also the entity representing the site.
The location of the link affects its strength
The “sourceType” function shows the relationship between the value of the page and where it is located. The higher the site level and the fresher the subpage date, the stronger the links from it. The most valuable links come from the homepage, especially if it is regularly updated.

Homepage PageRank affects subpages
It appears that each subpage borrows the reputation of the homepage before it builds its own PageRank (measured by click signals and other behavioral factors).

This means that new subpages of a strong site will rank higher initially because they are inherently more trustworthy. Only over time, based on user behavior, does Google determine the actual usefulness of the content. This way, a subpage of a weaker site can be promoted if its content is truly more valuable.
Google considers font size
Surprisingly, Google assesses every detail, including the average font size, as a ranking factor. Presumably, both extremes (too small or too large fonts) hinder readability, resulting in a lower rank.

Interestingly, the font size for anchor text is also evaluated.

Originality of text important even for short content
Not only extensive articles have SEO potential. Through the “OriginalContentStore” function, Google evaluates concise content for originality—likely to rank short but useful terms, such as online dictionaries.

Page title is a key parameter
The leaked documentation indicates that matching the title to the user’s query increases the page’s visibility. This is handled by the “titlematchScore” function.

Freshness matters
It has long been known that Google promotes fresh information. Now we have confirmation, expressed in several functions:
bylineDate – the visible date on the page.
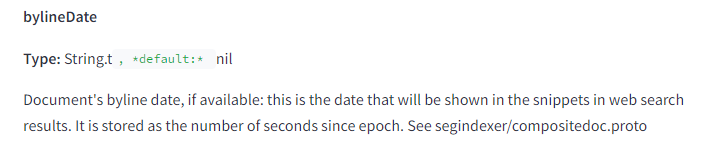
syntaticDate – the date visible in the URL or title.

semanticDate – the date included in the page content.

Thus, Google assesses not only the publication date but also the dates used in the content. It’s beneficial to cite current reports and studies to improve SEO results.
Sites with videos are treated differently
The “isVideoFocusedSite” function indicates that if more than half of the subpages contain videos, Google intervenes in the site’s rankings; however, we don’t know how.

Health-related sites indexed differently
There is a parameter named “ymylNewsScore” that relates to sites that could impact the health or life of its readers (YMYL – Your Money or Your Life). It seems that YMYL sites are ranked by different rules.
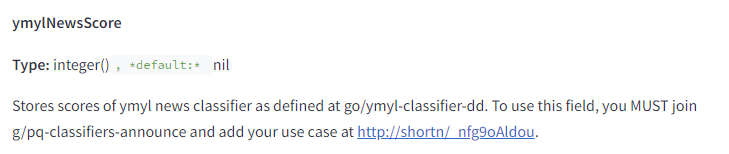
Google assigns the YMYL attribute not only to websites but even to specific queries.
Small personal sites get special treatment
The Google data leak revealed a mysterious ranking factor called “smallPersonalSite.” We don’t know how “small, personal sites” are defined and for what purpose.
We can guess that small businesses receive assistance in the initial phase of building visibility to quickly generate first traffic to the site. Perhaps this function is a reaction to the Helpful Content Update, which caused a significant drop in visibility for smaller sites in favor of better-optimized ones.

Google evaluates if you stay on topic
Algorithms value content related to the site’s theme more highly. The “QualityAuthorityTopicEmbeddingsVersionedItem” function checks if you publish content from your field or if you deviate too much from the topic.
The article is a substantial summary of iPullRank publication, which conducted a direct analysis of the code. If you want to know more details, we refer you to the source, where there are more conclusions.
Summary
We received many insights into how SEO algorithms work. However, it’s not hard to feel that there’s no big sensation in the Google leak.
For many years, Google has clearly indicated what it pays attention to when evaluating a site. It turns out that the leaked information is merely a technical confirmation of its guidelines. The data leak only reinforced the view that:
- Creating valuable content and maintaining high site quality is crucial.
- There are no shortcuts—regular work, content development, and continuous site optimization are necessary.
- To effectively position your site, it genuinely has to deserve it.
Analyzing ranking factors is a bit like analyzing a poem. You can examine its structure line by line, study stylistic devices… but that won’t make you write brilliant poetry immediately.
Similarly, with SEO – you can delve into theory and read about each function individually, but only action and creating valuable content will allow you to achieve a high position. Contrary to appearances, it’s more art than technicalities.
















Leave a Reply